Building a Multi-Agent RAG AI Interviewer: A Systems Engineering Approach
Job hunting often feels like a glitch in the Matrix — repeating the same stories over and over. It is a bottleneck for candidates and recruiters who are often overwhelmed by hundreds of resumes.
What if you could deploy a version of yourself — informed by your entire career history, speaking in your actual voice — to handle that first-round screening?
I built ai-interview.billhansen.net to move past the "chatbot" era and into true agentic systems engineering. This isn't a demo; it's a production system utilizing four different LLM providers, six specialized agents, and a multi-path routing engine. This post explores why a multi-agent approach is superior to a monolithic prompt and how RAG transforms static career data into a living conversation.
The Multi-Agent Pipeline: One Prompt Wasn't Enough
In early iterations, a single, massive system prompt was used and failed. The model would suffer from "tone drift," hallucinate experience, or fail to identify when a position was a poor fit. To solve this, the logic was decentralized into a four-stage pipeline where each agent has a narrow, testable job.
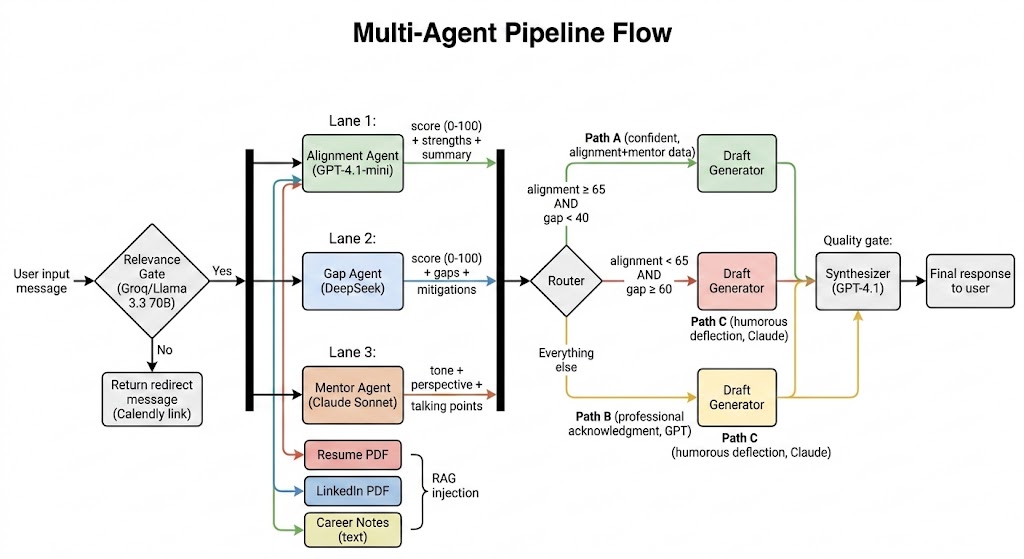
Stage 1: The Relevance Gate (Groq / Llama 3.3 70B)
Speed is the priority. Groq's sub-second inference identifies if a query is on-topic. If a visitor expresses frustration with talking to a bot, the system redirects them to a Calendly link immediately to schedule a phone call.
Stage 2: Parallel Analysis (The Committee)
If the input is relevant, it hits three agents concurrently:
- Alignment Agent (GPT-4.1-mini): Quantifies how well the visitor's needs match my technical background on a 0–100 scale.
- Gap Agent (DeepSeek): Specifically hunts for missing skills. It handles JSON extraction to ensure the system addresses concerns head-on.
- Mentor Agent (Claude Sonnet): Claude provides the creative framing, ensuring the response feels nuanced and professional rather than robotic.
Stage 3: Deterministic Routing
Instead of letting an LLM "feel" its way to a response, the system uses hard-coded numerical thresholds. If Alignment ≥ 65 and Gap < 40, we follow Path A (Confident). If gaps are high, Path B provides professional acknowledgment and strategy to close the gap. If alignment is low and gaps are significant, Path C delivers a witty, self-aware deflection.
Stage 4: The Synthesizer (GPT-4.1)
The strongest model takes the drafted path and rewrites it in my voice. It follows strict rules: first person, specific project names, and a ban on generic corporate filler like "I appreciate the opportunity" or "I love collaborating."
RAG: Career Context as Living Documents
Fine-tuning a model on a resume is a dead end. Career history is a living document — new skills are acquired and projects are completed monthly. Fine-tuning is too slow and expensive.
Instead, I use Retrieval-Augmented Generation (RAG). At runtime, the system parses my Resume, LinkedIn profile, and Career Notes. The notes contain the "why" behind specific moves — leadership philosophies and project impacts that don't fit in a bullet point. These are injected directly into the Stage 2 agents' context.
Session Lifecycle & Persistence: Remembering the Conversation
A professional interview doesn't happen in a vacuum. If a recruiter ends an interview session and later returns, the AI remembers where they left off. I used PostgreSQL with Prisma to manage the session state.
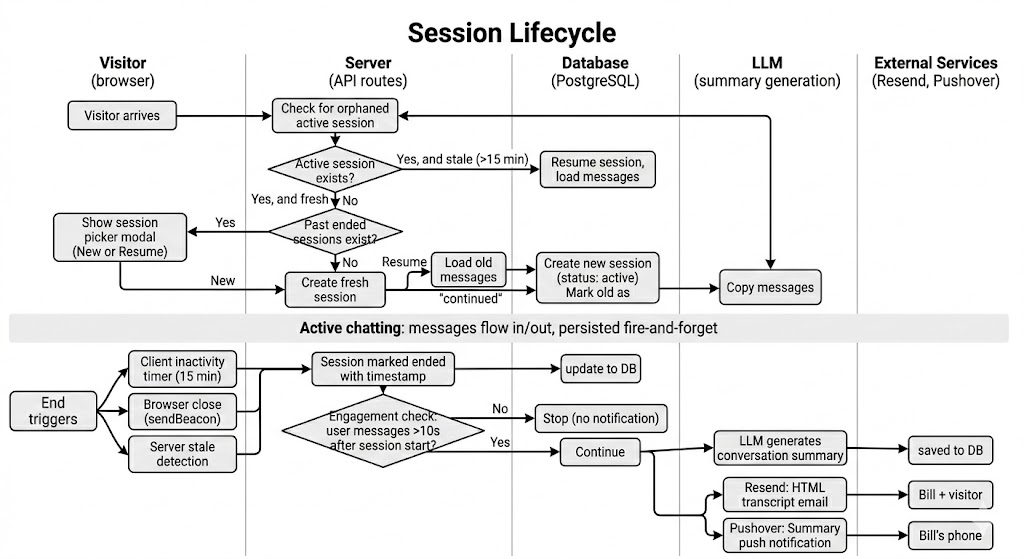
Sessions move through three states: active, ended, and continued (when a visitor resumes a previous conversation). Three mechanisms can end a session:
- Client inactivity timer — 15 minutes of no interaction
- Browser close — caught via
sendBeacon - Server stale detection — checked when a visitor returns
To keep the UI snappy, message persistence is "fire-and-forget" — we render the AI response to the user immediately and save it to the database asynchronously.
The system also includes Stale Detection. If a session has been inactive for 15 minutes, it is automatically ended, triggering a notification pipeline that sends a mobile push notification and a styled HTML transcript to the interviewer's email and my email consisting of a summary and the transcript of the interview.
Input Channels & Moderation: More Than Text
Interviews happen through voice and documents, not just typing. The system supports three channels: Text, File uploads (PDF/DOCX/Images), and Voice (via MediaRecorder and Whisper STT).
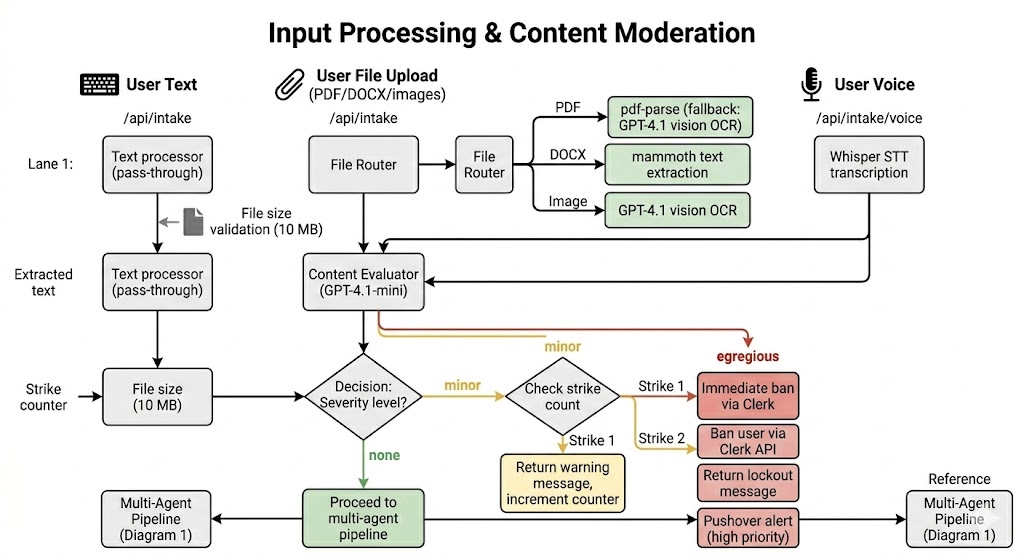
Because this is a public-facing application, security and moderation are important. Every input is classified by GPT-4.1-mini. A "minor" infraction of the Terms of Service results in a first strike warning; an "egregious" violation results in an immediate ban via the Clerk API.
The Notification Pipeline: Closing the Loop
The system isn't useful if I don't know it's working. When a session ends with real engagement, the "Post-Game" pipeline triggers:
- LLM Summary: A model summarizes the entire chat.
- Resend: Sends a beautiful, dark-themed HTML transcript to both me and the visitor, including a Calendly CTA.
- Pushover: Sends a high-priority push notification to my phone so I can review the interaction in real-time.
Tech Choices & Trade-offs
- Multi-Model Orchestration: Groq provides the speed needed for gates; DeepSeek provides cost-effective structured data; Claude offers the best prose; and GPT-4.1 serves as the final quality gate.
- Infrastructure: The site runs on Next.js with Docker and is hosted on Railway, ensuring a small, scalable footprint.
- Auth & Security: Clerk handles the authentication and "Ban" infrastructure, allowing me to focus on the AI logic rather than building an auth system from scratch.
The Project is the Interview
In modern engineering, demonstrating how a system fails and recovers is just as important as showing it work. This project is my "Interview" — it demonstrates an ability to handle state, multi-model orchestration, and production-grade moderation.
Ready to chat? Try the system at ai-interview.billhansen.net.